2 Coding in R
Welcome to Posit Cloud! You made it! This document will introduce you to how to start coding in R, using Posit Cloud. We will use the R statistical coding language frequently in class to conduct analyses and visualization.
Hello world! We are coding in R!
Getting Started
Making an Posit.Cloud account
We’ll be using Posit.Cloud, a virtual version of R you can access from any computer with an internet browser (PC, Mac, Chromebook, anything). To get set up, please follow the steps in this short Video playlist!

2.1 Introduction to R
The document in your Posit Cloud project document is an ‘R script.’ (its name ends in .R).
It contains two kinds of text:
‘code’ - instructions to our statistical calculator
‘comments’ - any text that immediately follows a ‘#’ sign.
Notice: 4 windows in R.
Window 1 (upper left): Scripts!
Window 2 (bottom left): Console (this shows the output for our calculator)
Window 3 (upper right): Environment (this shows any data the computer is holding onto for us)
Window 4 (bottom right): Files (this shows our working project folder, our scripts, and any data files.)
A few tips:
To change the background theme (and save your eyes), go to Tools >> Global Options >> Appearance >> Editor Theme >> Dracula
To increase the font size, go to Tools >> Global Options >> Appearance >> Editor Font Size
To make a script, go to File >> New File >> R Script, then save it and name it.
(#fig:image_1_1)Open New Script
(#fig:image_1_2)Save New Script!
Let’s learn to use R!
2.2 Basic Calculations in R
Try highlighting the following with your cursor, and then press CTRL and ENTER simultaneously, or the ‘Run’ button above.
Addition:
## [1] 6Subtraction:
## [1] 3Multiplication:
## [1] 6Division:
## [1] 3Exponents:
## [1] 4Square-Roots:
## [1] 2Order of Operations:
Still applies! Like in math normally, R calculations are evaluated from left to right, prioritizing parentheses, then multiplication and division, then addition and subtraction.
## [1] -1Use Parentheses!
## [1] -6
Learning Check 1
Learning Checks (LC) are short questions that appear throughout this book, providing short coding challenges to try and work through.
Below is the
questiontab.Read the question, and try to answer it on your own!
Then, click the answer button to see the
answer. (Note: There are often many different ways to code the same thing!)Feeling stumped? You can check the answer, but be sure to code it yourself afterwards!
Question
Try calculating something wild in R! Solve for x below using the commands you just learned in R!
\(x = \sqrt{ (\frac{2 - 5 }{5})^{4} }\)
\(x = (1 - 7)^{2} \times 5 - \sqrt{49}\)
\(x = 2^{2} + 2^{2} \times 2^{2} - 2^{2} \div 2^{2}\)
[View Answer!]
Here’s how we coded it! How does yours compare? If your result is different, compare code. What’s different? Be sure to go back and adjust your code so you understand the answer!
- \(x = \sqrt{ (\frac{2 - 5 }{5})^{4} }\)
## [1] 0.36- \(x = (1 - 7)^{2} \times 5 - \sqrt{49}\)
## [1] 173- \(x = 2^{2} + 2^{2} \times 2^{2} - 2^{2} \div 2^{2}\)
## [1] 19
2.3 Types of Values in R
R accepts 2 type of data:
## [1] 15000## [1] 5e-04## [1] -8222and
## [1] "Coding!"## [1] "Corgis!"## [1] "Coffee!"(Note: R also uses something called factors, which are characters, but have a specific order. We’ll learn them later.)
2.4 Types of Data in R
2.4.1 Values
First, R uses values - which are single numbers or characters.
## [1] 2## [1] "x"You can save a value as a named object in the R Environment.
That means, we tell R to remember that whenever you use a certain name, it means that value.
To name something as an object, use an arrow!
Now let’s highlight and press CTRL ENTER on myvalue (or the Mac Equivalent).
## [1] 2Notice how it’s listed in the R Environment (upper right), and how it outputs as 2 in the console?
We can do operations too!
## [1] 4We can also overwrite old objects with new objects.
## [1] "I overwrote it!"And we can also remove objects from the Environment, with remove().
2.4.2 Vectors
Second, R contains values in vectors, which are sets of values.
## [1] 1 4 8and…
## [1] "Boston" "New York" "Los Angeles"But if you combine numeric and character values in one vector…
## [1] "1" "Boston" "2"Why do we use vectors? Because you can do mathematical operations on entire vectors of values, all at once!
## [1] 2 4 6 8## [1] 3 4 5 6We can save vectors as objects too!
# Here's a vector of (hypothetical) seawall heights in 10 towns.
myheights <- c(4, 4.5, 5, 5, 5, 5.5, 5.5, 6, 6.5, 6.5)
# And here's a list of hypothetical names for those towns
mytowns <- c("Gloucester", "Newburyport", "Provincetown",
"Plymouth", "Marblehead", "Chatham", "Salem",
"Ipswich", "Falmouth", "Boston")
# And here's a list of years when those seawalls were each built.
myyears <- c(1990, 1980, 1970, 1930, 1975, 1975, 1980, 1920, 1995, 2000)Plus, we can still do operations on entire vectors!
## [1] 1991 1981 1971 1931 1976 1976 1981 1921 1996 20012.4.3 Dataframes
Third, R bundles vectors into data.frames.
# Using the data.frame command, we make a data.frame,
data.frame(
height = myheights, # length 10
town = mytowns, # length 10
year = myyears) # length 10## height town year
## 1 4.0 Gloucester 1990
## 2 4.5 Newburyport 1980
## 3 5.0 Provincetown 1970
## 4 5.0 Plymouth 1930
## 5 5.0 Marblehead 1975
## 6 5.5 Chatham 1975
## 7 5.5 Salem 1980
## 8 6.0 Ipswich 1920
## 9 6.5 Falmouth 1995
## 10 6.5 Boston 2000And inside, we put a bunch of vectors of EQUAL LENGTHS, giving each vector a name.
And when it outputs in the console, it looks like a spreadsheet!
BECAUSE ALL SPREADSHEETS ARE DATAFRAMES!
AND ALL COLUMNS ARE VECTORS!
AND ALL CELLS ARE VALUES!
Actually, we can make data.frames into objects too!
# Let's name our data.frame about seawalls 'sw'
sw <- data.frame(
height = myheights,
town = mytowns,
year = myyears) # Notice this last parenthesis; very important
# Check the contents of sw!
sw## height town year
## 1 4.0 Gloucester 1990
## 2 4.5 Newburyport 1980
## 3 5.0 Provincetown 1970
## 4 5.0 Plymouth 1930
## 5 5.0 Marblehead 1975
## 6 5.5 Chatham 1975
## 7 5.5 Salem 1980
## 8 6.0 Ipswich 1920
## 9 6.5 Falmouth 1995
## 10 6.5 Boston 2000Although, we could do this too, and it would be equivalent:
sw <- data.frame(
# It's okay to split code across multiple lines.
# It keeps things readable.
height = c(4, 4.5, 5, 5, 5,
5.5, 5.5, 6, 6.5, 6.5),
town = c("Gloucester", "Newburyport", "Provincetown",
"Plymouth", "Marblehead", "Chatham", "Salem",
"Ipswich", "Falmouth", "Boston"),
year = c(1990, 1980, 1970, 1930, 1975,
1975, 1980, 1920, 1995, 2000))
# Let's check out our dataframe!
sw## height town year
## 1 4.0 Gloucester 1990
## 2 4.5 Newburyport 1980
## 3 5.0 Provincetown 1970
## 4 5.0 Plymouth 1930
## 5 5.0 Marblehead 1975
## 6 5.5 Chatham 1975
## 7 5.5 Salem 1980
## 8 6.0 Ipswich 1920
## 9 6.5 Falmouth 1995
## 10 6.5 Boston 2000But what if we want to work with the vectors again?
We can use the ‘$’ sign to say, ‘grab the following vector from inside this data.frame.’
## [1] 4.0 4.5 5.0 5.0 5.0 5.5 5.5 6.0 6.5 6.5We can also do operations on that vector from within the dataframe.
## [1] 5.0 5.5 6.0 6.0 6.0 6.5 6.5 7.0 7.5 7.5We can also update values, like the following:
# sw$height <- sw$height + 1
# I've put this in comments, since I don't actually want to do it (it'll change our data)
# but good to know, right?
Learning Check 2
Question
How would you make your own data.frame?
Please make up a data.frame of with 3 vectors and 4 values each. Make 1 vector numeric and 2 vectors character data. How many rows are in that data.frame?
[View Answer!]
Here’s my example!
# Make a data.frame called 'mayhem'
mayhem <- data.frame(
# make a character vector of 4 dog by their names
dogs = c("Mocha", "Domino", "Latte", "Dot"),
# Classify the type of dog as a character vector
types = c("corgi", "dalmatian", "corgi", "dalmatian"),
# Record the number of treats eaten per year per dog
treats_per_year = c(5000, 3000, 2000, 10000))
# View the resulting 'mayhem'!
mayhem## dogs types treats_per_year
## 1 Mocha corgi 5000
## 2 Domino dalmatian 3000
## 3 Latte corgi 2000
## 4 Dot dalmatian 10000
2.5 Common Functions in R
We can also run functions that come pre-installed to analyze vectors.
These include: mean(), median(), sum(), min(), max(), range(), quantile(), sd(), var(), and length().

(#fig:image_1_4)Descriptive Stats function Cheatsheet!
2.6 Missing Data
Sometimes, data.frames include missing data for a case/observation. For example, let’s say there is an 11th town, where the seawall height is unknown.
# We would write:
mysw <- c(4, 4.5, 5, 5, 5,
5.5, 5.5, 6, 6.5, 6.5, NA) # see the 'NA' for non-applicableIf you run mean(mysw) now, R doesn’t know how to add 6.5 + NA.
The output will become NA instead of 5.35.
## [1] NATo fix this, we can add an ‘argument’ to the function, telling it to omit NAs from the calculation.
## [1] 5.35Pretty cool, no?
Each function is unique, often made by different people, so only these functions have na.rm as an argument.
Learning Check 3
Question
Jun Kanda (2015) measured max seawall heights (seawall_m) in 13 Japanese towns (town) after the 2011 tsunami in Tohoku, Japan, compared against the height of the tsunami wave (wave_m). Using this table, please code and answer the questions below.
| town | seawall_m | wave_m |
|---|---|---|
| Kuji South | 12.0 | 14.5 |
| Fudai | 15.5 | 18.4 |
| Taro | 13.7 | 16.3 |
| Miyako | 8.5 | 11.8 |
| Yamada | 6.6 | 10.9 |
| Ohtsuchi | 6.4 | 15.1 |
| Tohni | 11.8 | 21.0 |
| Yoshihama | 14.3 | 17.2 |
| Hirota | 6.5 | 18.3 |
| Karakuwa East | 6.1 | 14.4 |
| Onagawa | 5.8 | 18.0 |
| Souma | 6.2 | 14.5 |
| Nakoso | 6.2 | 7.7 |
Reproduce this table as a data.frame in R, and save it as an object named
jp.How much greater was the mean height of the tsunami than the mean height of seawalls?
Evaluate how much these heights varied on average among towns. Did seawall height vary more than tsunami height? How much more/less?
[View Answer!]
- Reproduce this table as a data.frame in R, and save it as an object named
jp.
# Make a dataframe named jp,
jp <- data.frame(
# containing a character vector of 13 town names,
town = c("Kuji South", "Fudai", "Taro", "Miyako", "Yamada", "Ohtsuchi", "Tohni",
"Yoshihama", "Hirota", "Karakuwa East", "Onagawa", "Souma", "Nakoso"),
# and a numeric vector of 13 max seawall heights in meters
seawall_m = c(12.0, 15.5, 13.7, 8.5, 6.6, 6.4, 11.8, 14.3, 6.5, 6.1, 5.8, 6.2, 6.2),
# and a numeric vector of 13 max tsunami heights in meters
wave_m = c(14.5, 18.4, 16.3, 11.8, 10.9, 15.1, 21.0, 17.2, 18.3, 14.4, 18.0, 14.5, 7.7)
)
# View contents!
jp## town seawall_m wave_m
## 1 Kuji South 12.0 14.5
## 2 Fudai 15.5 18.4
## 3 Taro 13.7 16.3
## 4 Miyako 8.5 11.8
## 5 Yamada 6.6 10.9
## 6 Ohtsuchi 6.4 15.1
## 7 Tohni 11.8 21.0
## 8 Yoshihama 14.3 17.2
## 9 Hirota 6.5 18.3
## 10 Karakuwa East 6.1 14.4
## 11 Onagawa 5.8 18.0
## 12 Souma 6.2 14.5
## 13 Nakoso 6.2 7.7- How much greater was the mean height of the tsunami than the mean height of seawalls?
## [1] 15.23846The average wave was 15.24 meters tall.
## [1] 9.2The average seawall was 9.2 meters tall.
## [1] 6.038462The average wave was 6.04 meters taller than the average seawall.
- Evaluate how much these heights varied on average among towns. Did seawall height vary more than tsunami height? How much more/less?
## [1] 3.587603On average, wave height varied by 3.59 meters.
## [1] 3.675368On average, seawall height varied by 3.68 meters.
## [1] -0.08776516That means wave height varied by -0.09 meters less than seawall height.
2.7 Packages
2.7.1 Using Packages
Some functions come pre-built into R, but lots of people have come together to build ‘packages’ of functions that help R users all over the world do more, cool things, so we don’t each have to ‘reinvent the wheel.’ ggplot2, which we use below, is one of these!
2.7.2 Installing Packages
We can use the library() function to load a package (like fipping an ‘on’ switch for the package). After loading it, R will recognize that package’s functions when you run them!
But if you try to load a package that has never been installed on your computer, you might get this error:
Error in library(ggplot2) : there is no package called ‘ggplot2’
In this case, we need to install those packages (only necessary once), using install.packages(). (If a message pops up, just accept ‘Yes’.)
After a successful install, you’ll get a message like this:
==================================================
downloaded 1.9 MB
* installing *binary* package ‘ggplot2’ ...
* DONE (ggplot2)
* installing *binary* package ‘dplyr’ ...
* DONE (dplyr)
The downloaded source packages are in
‘/tmp/RtmpefCnYe/downloaded_packages’The Pipeline
In much of this course, we’re going to use a coding symbol %>%, called a pipeline. The pipeline is not built into base R, so you always need the dplyr package loaded in order to use it. Fortunately, we just loaded dplyr, our data wrangling toolkit, above using library(dplyr), so we’re good to go!
Pipelines let us connect data to functions, with fewer parentheses! It helps more clearly show and code a process of input data to function A to function B to output data (for example).

Figure 2.1: Old-School Pipeline
For example:
## [1] 2## [1] 2Using pipelines keeps our code neat and tidy. It lets us run long sequences of code without saving it bit by bit as objects. For example, we can take them mean() of x and then get the length() of the resulting vector, all in one sequence. Without a pipeline, you end up in parenthesis hell very quickly.
## [1] 1## [1] 1Handy, right? To simplify things, there’s a special ‘hotkey’ shortcut for making pipelines too. In Windows and Linux, use Ctrl Shift M. In Mac, use Cmd Shift M.
2.8 Visualizing Data with Histograms
The power of R is that you can process data, calculate statistics, and visualize it all together, very quickly. We can do this using hist() and geom_histogram(), among other functions.
2.8.1 hist()
For example, let’s imagine that we had seawall height data from cities in several states. We might want to compare those states.
# Create 30 cities, ten per state (MA, RI, ME)
allsw <- data.frame(
height = c(4, 4.5, 5, 5, 5.5, 5.5, 5.5, 6, 6, 6.5,
4, 4,4, 4, 4.5, 4.5, 4.5, 5, 5, 6,
5.5, 6, 6.5, 6.5, 7, 7, 7, 7.5, 7.5, 8),
states = c("MA","MA","MA","MA","MA","MA","MA","MA","MA","MA",
"RI","RI","RI","RI","RI","RI","RI","RI","RI","RI",
"ME","ME","ME","ME","ME","ME","ME","ME","ME","ME"))
# Take a peek!
allsw## height states
## 1 4.0 MA
## 2 4.5 MA
## 3 5.0 MA
## 4 5.0 MA
## 5 5.5 MA
## 6 5.5 MA
## 7 5.5 MA
## 8 6.0 MA
## 9 6.0 MA
## 10 6.5 MA
## 11 4.0 RI
## 12 4.0 RI
## 13 4.0 RI
## 14 4.0 RI
## 15 4.5 RI
## 16 4.5 RI
## 17 4.5 RI
## 18 5.0 RI
## 19 5.0 RI
## 20 6.0 RI
## 21 5.5 ME
## 22 6.0 ME
## 23 6.5 ME
## 24 6.5 ME
## 25 7.0 ME
## 26 7.0 ME
## 27 7.0 ME
## 28 7.5 ME
## 29 7.5 ME
## 30 8.0 MEEvery vector is a distribution - a range of low to high values. We can use the hist() function to quickly visualize a vector’s distribution.
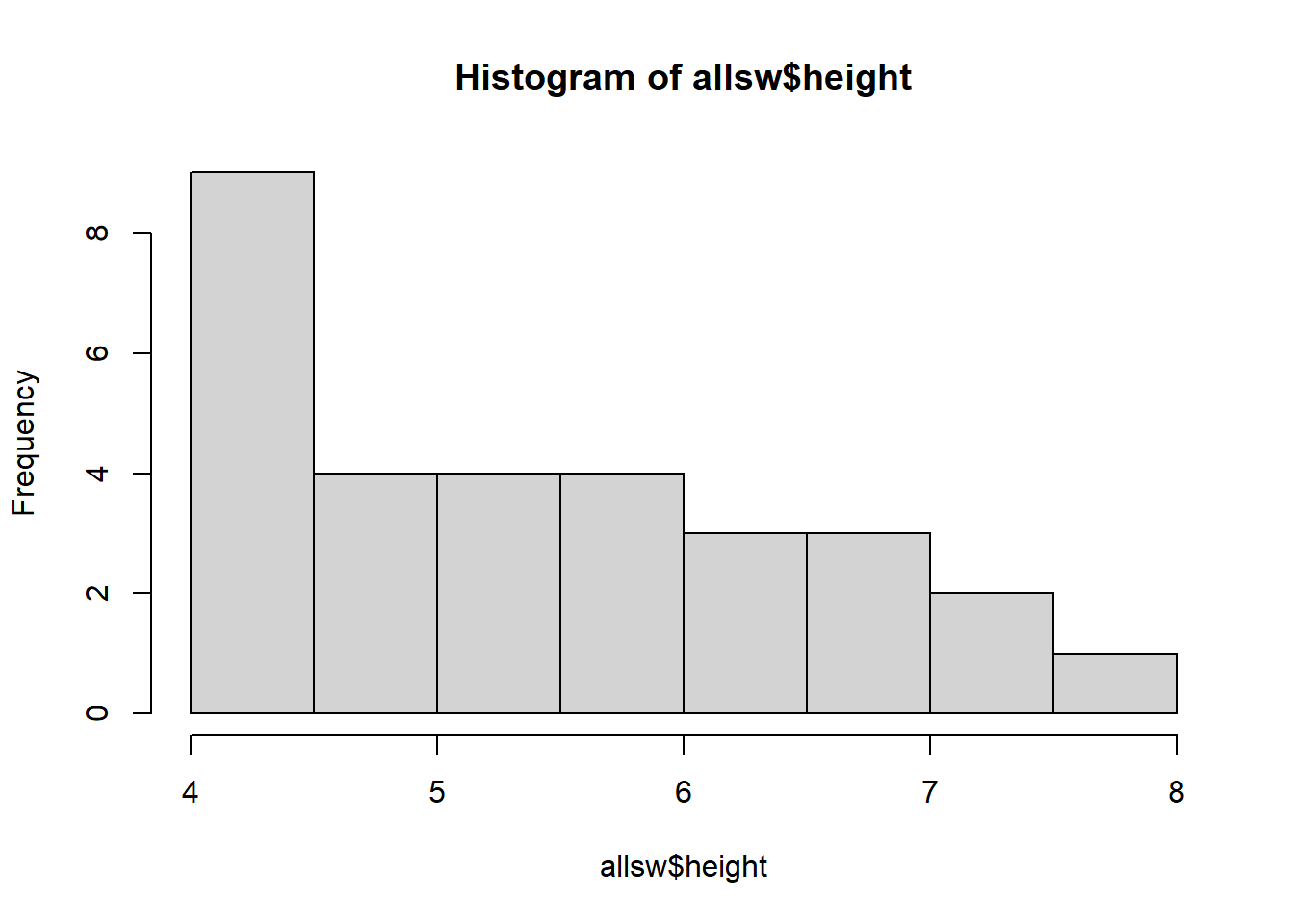
Learning Check 4
Question
Using the hist() function we just learned, draw the histogram of a vector of seawalls, naming the vector sw! The vector should include the following seawall heights (in meters): 4.5 m, 5 m, 5.5 m, 5 m, 5.5 m, 6.5 m, 6.5 m, 6 m, 5 m, and 4 m.
[View Answer!]
Using the hist() function we just learned, draw the histogram of a vector of seawalls, naming the vector sw! The vector should include the following seawall heights (in meters): 4.5 m, 5 m, 5.5 m, 5 m, 5.5 m, 6.5 m, 6.5 m, 6 m, 5 m, and 4 m.
# Many options!
# You could code it as a vector, save it as an object, then use your functions!
sw <- c(4.5, 5, 5.5, 5, 5.5, 6.5, 6.5, 6, 5, 4)
sw %>% hist()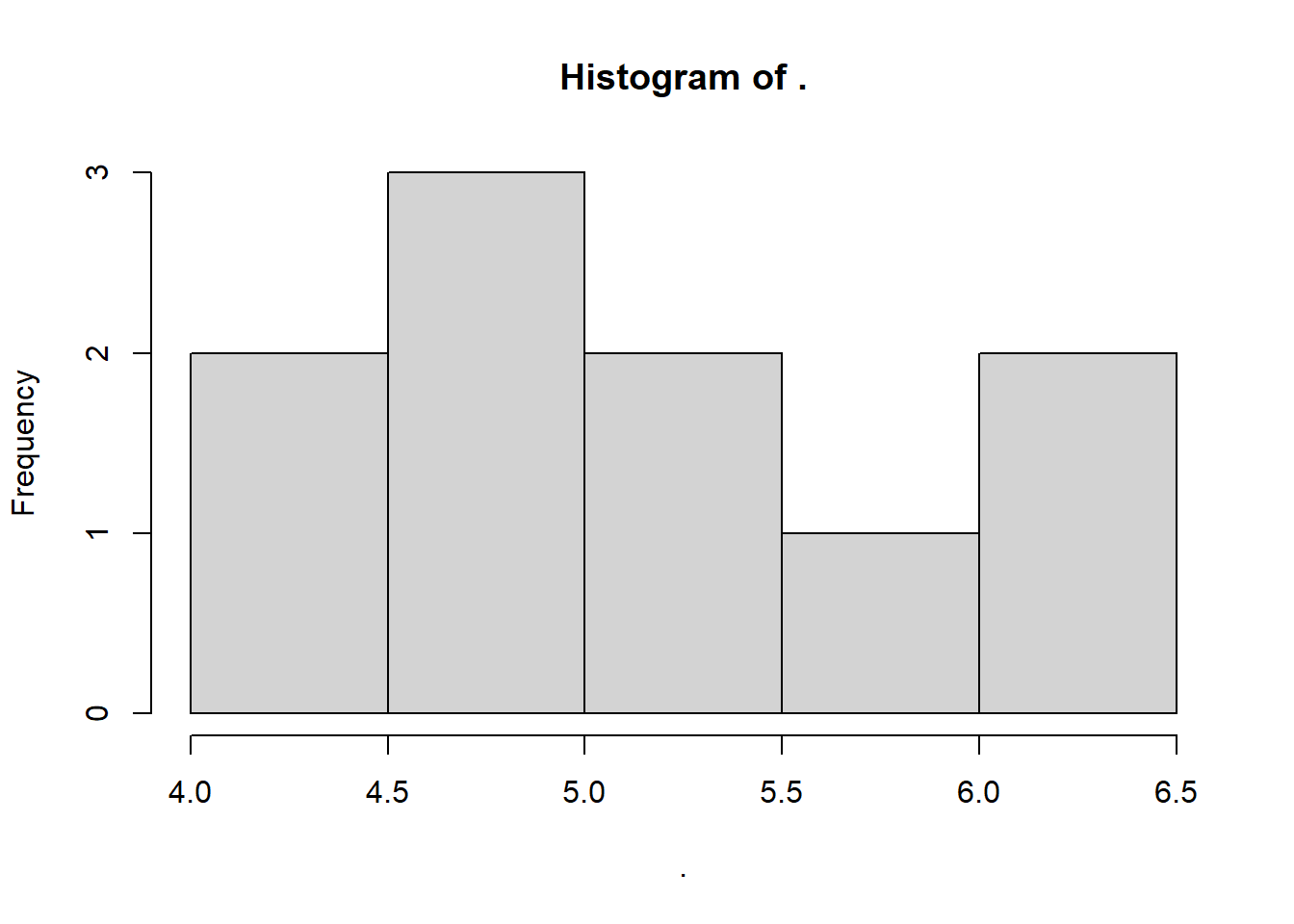
2.8.2 geom_histogram() in ggplot2
hist() is great for a quick check, but for anything more complex, we’re going to use ggplot2, the most popular visualization package in R.
# Load ggplot2 package
library(ggplot2)
# Tell the ggplot function to...
ggplot(
# draw data from the 'allsw' data.frame
data = allsw,
# and 'map' the vector 'height' to be an 'aes'thetic on the 'x'-axis.
mapping = aes(x = height)) +
# make histograms of distribution,
geom_histogram(
# With white outlines
color = "white",
# With blue inside fill
fill = "steelblue",
# where every half meter gets a bin (binwidth = 0.5)
binwidth = 0.5) +
# add labels
labs(x = "Seawall Height", y = "Frequency (# of cities)") 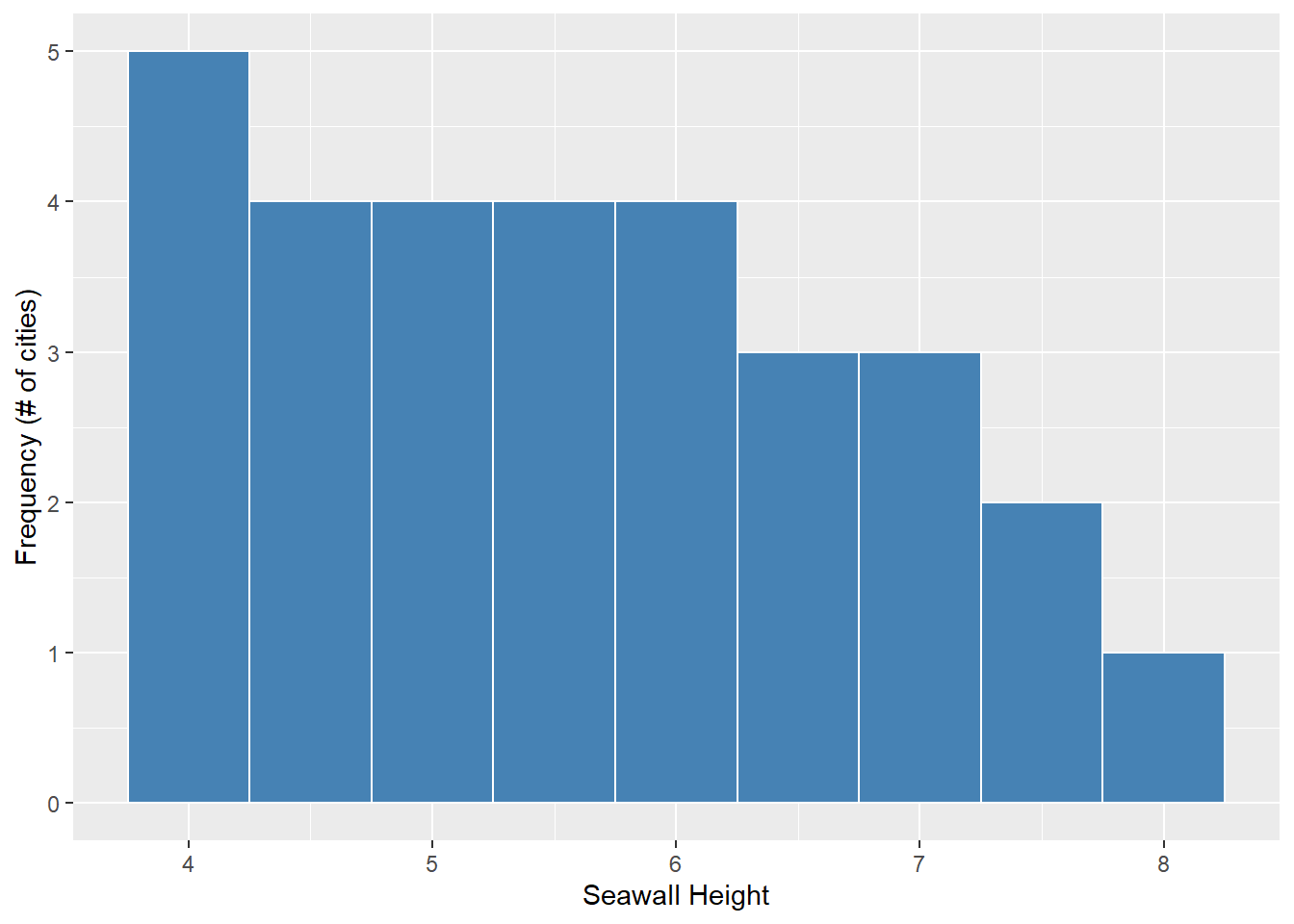
Looks much nicer, right? Lots more code, but lots more options for customizing. We’ll learn ggplot2 more over this term, and it will become second nature in time! (Just takes practice!)
The value of ggplot2 really comes alive when we make complex visuals. For example, our data allsw$height essentially contains 3 vectors, one per state; one for MA, one for RI, one for ME. Can we visualize each of these vectors’ distributions using separate histograms?
# Repeat code from before...
ggplot(data = allsw, mapping = aes(x = height)) +
geom_histogram(color = "white", fill = "steelblue", binwidth = 0.5) +
labs(x = "Seawall Height", y = "Frequency (# of cities)") + # don't forget the '+'!
# But also
## Split into panels by state!
facet_wrap(~states)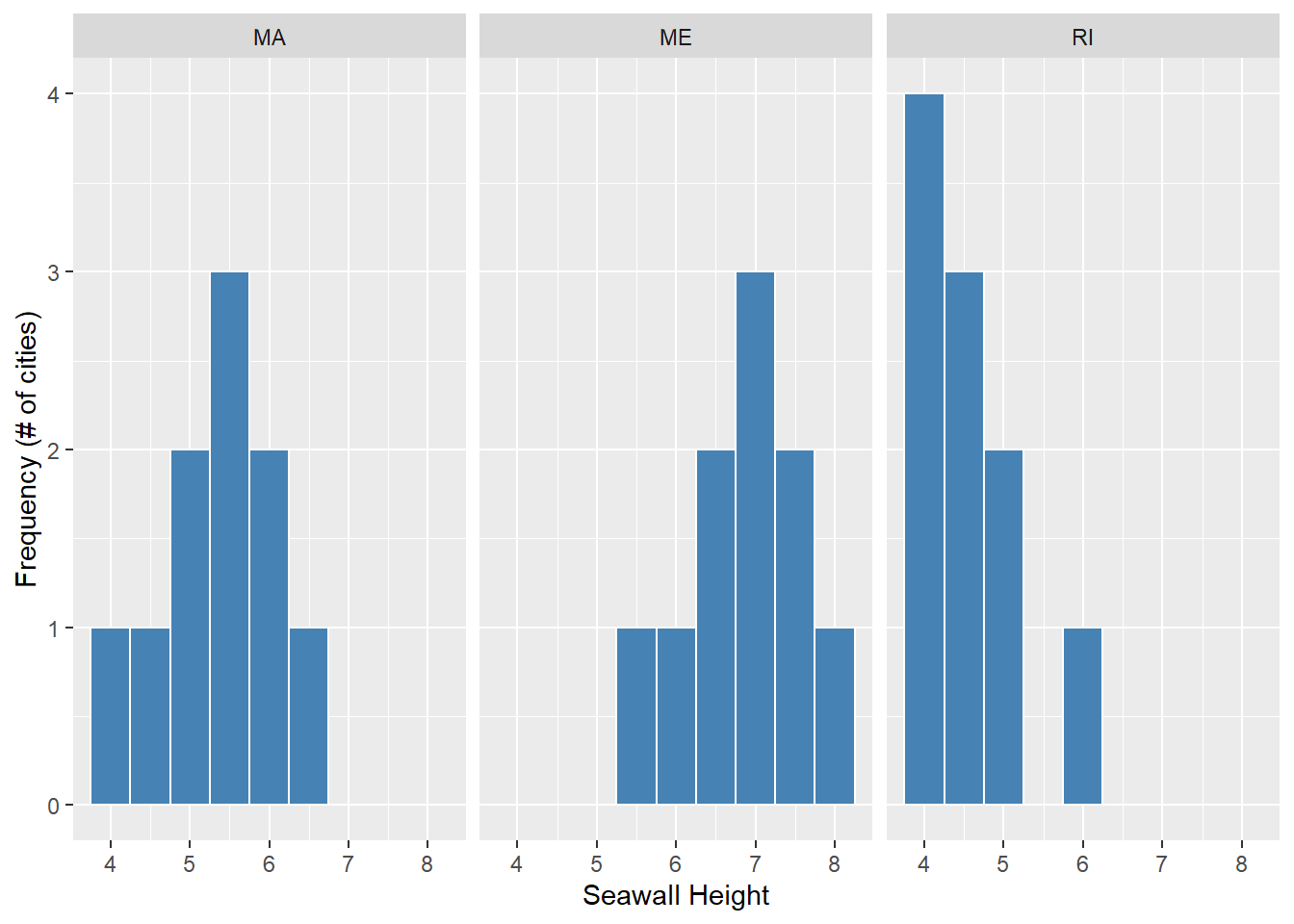
We can now see, according to our hypothetical example, that states host different distributions of seawall heights.
Massachusetts (MA) has lower seawalls, evenly distributed around 5.5 m. Maine (ME) has higher seawalls, skewed towards 7 m. Rhode Island (RI) has lower seawalls, skewed towards 4 m.
Learning Check 5
Question
Challenge: Please make a histogram of Jun Kanda’s sample of seawall heights (seawall_m) in the jp object from LC 3.
First, make a histogram using the
hist()function.Then, try and use the
geom_histogram()function fromggplot2!
[View Answer!]
- First, make a histogram using the
hist()function.
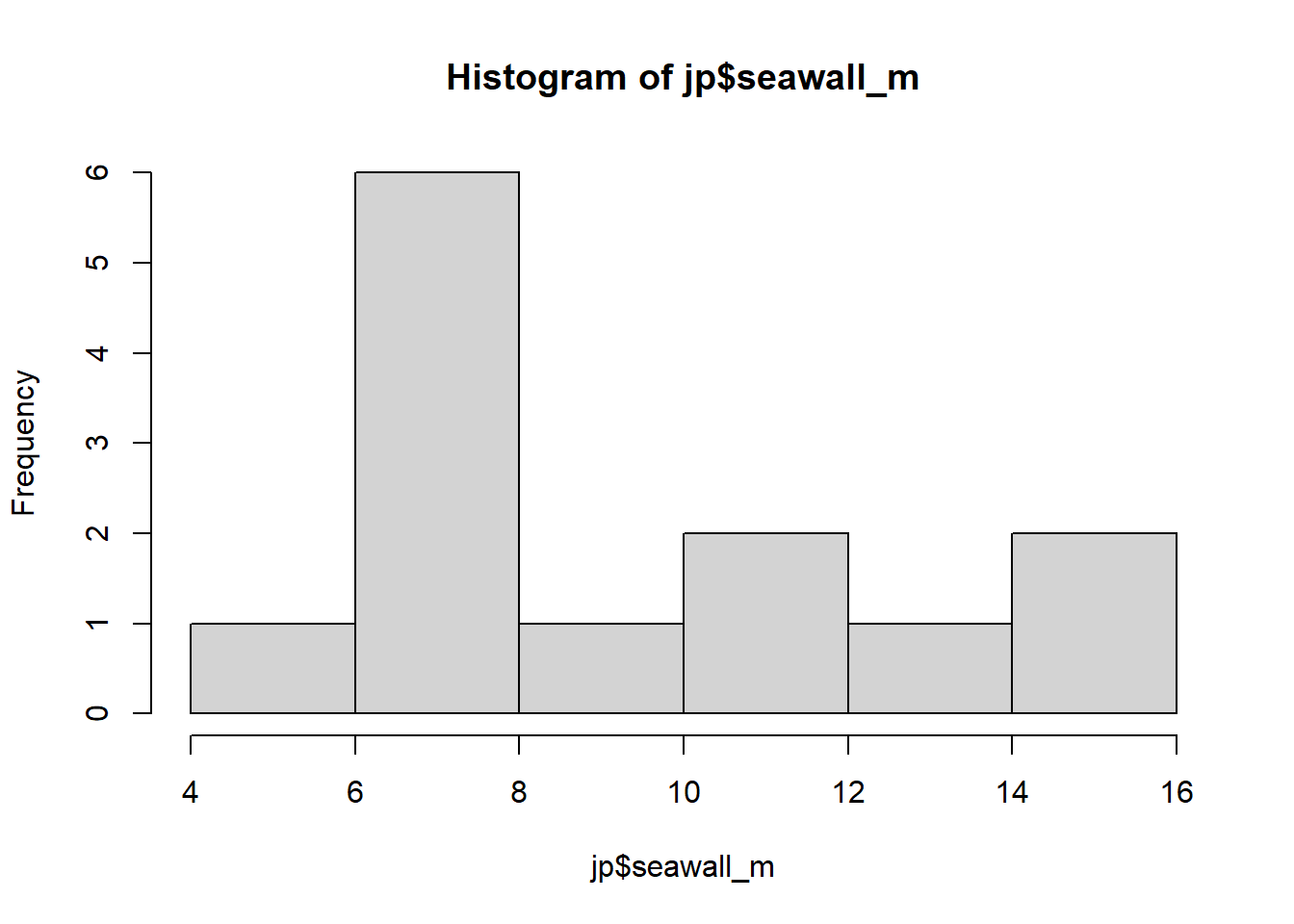
- Then, try and use the
geom_histogram()function fromggplot2!
# Tell ggplot to grab the 'seawall_m' vector from the 'jp' data.frame,
# and make a histogram!
ggplot(data = jp, mapping = aes(x = seawall_m)) +
geom_histogram()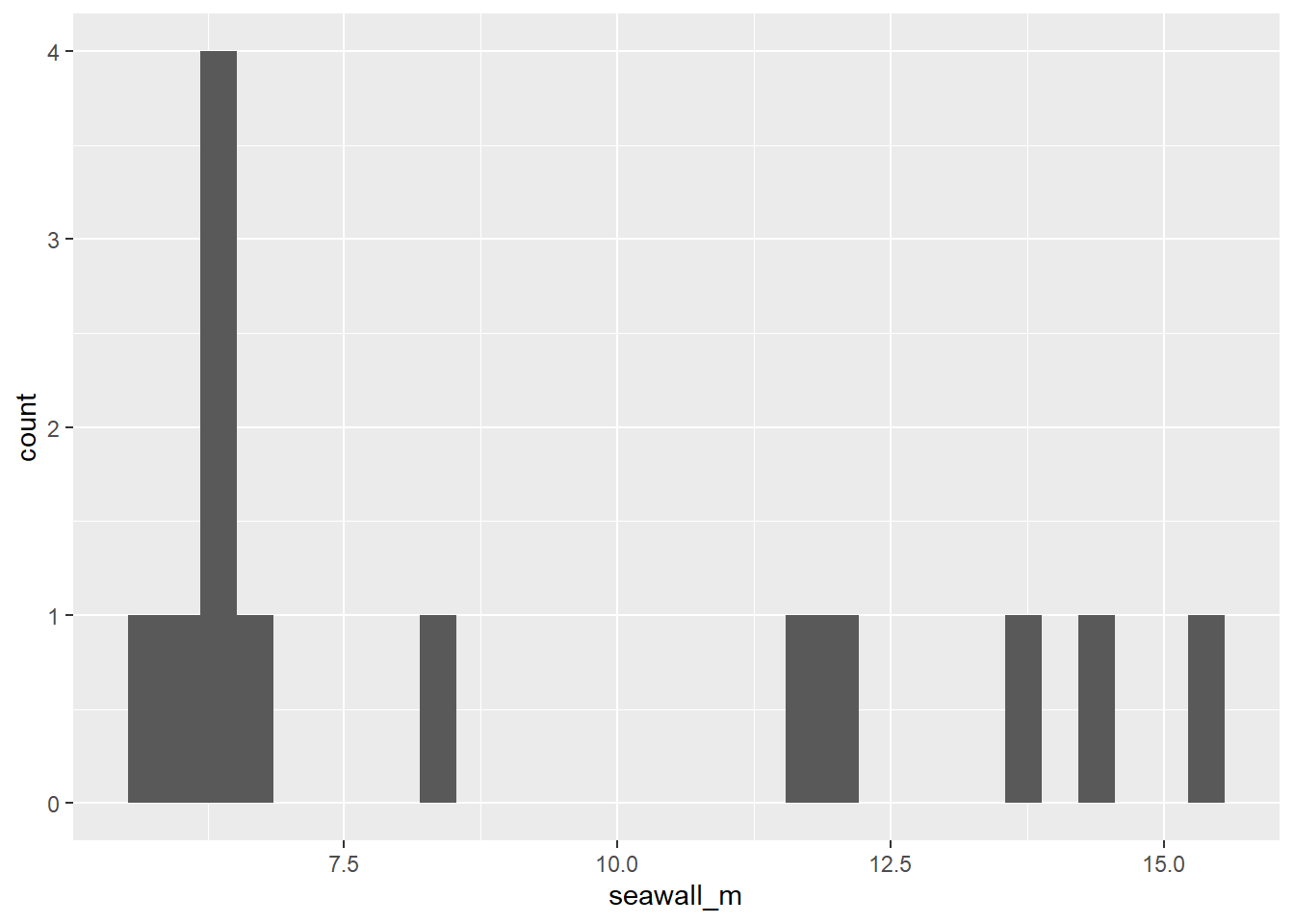
Looks pretty weird, huh? hist() automatically chooses the binwidth, but ggplot() gives us more control over the whole plot. We’ll learn more about this soon!
Conclusion
Next Steps
Throughout the rest of the course, we’re going to advance each of these skills:
working with types of data in R
calculating meaningful statistics in R
visualizing meaningful trends in R
Advice
Be sure to clear your environment often.
That means, using remove() or the broom tool in the upper right hand corner.
You can clean your console too, using broom in console’s upper right corner.
Save often. (Control + Save usually works on PC.)
You can download files using more / export, or upload them.
You’ll be a rockstar at using R in no time! Stay tuned for our next Workshop!
Troubleshooting
If your session freezes, go to ‘Session’ >> ‘Restart R.’
If that doesn’t work, go to ‘Session’ >> ‘Terminate’.
If that doesn’t work, click on the elipsis (…) in the white banner at the top, and select Relaunch Project.
If that doesn’t work, let me know!
Having problems? There are three causes of most all problems in R.
there’s a missing parenthesis or missing quotation mark in one’s code.
You’re using a function from a package that needs to be loaded (we’ll talk about this in later workshops).
Too much data in your environment is causing R to crash. Clear the environment.